佛系程序员
首页
栏目
标签
归档
关于
友链
佛系程序员
首页
栏目
标签
归档
友链
关于
音视频转文字工具线上部署宝塔面板
学习笔记
网站开发
发布日期: 2025-05-24 16:56:20
喜欢量: 9 个
阅读次数:
918
宝塔面板
阿里云服务器:99元/年的2核2G,3Mbps 系统:Alibaba Cloud 3 (OpenAnolis Edition) x86_64(Py3.7.16) 宝塔面板:免费版9.5.0 ****登录「宝塔面板」,进入「终端」 cd /www/wwwroot # 替换为你希望存放项目的目录 git clone https://gitee.com/phpervip/speech-to-text.git cd speech-to-text pip install -r requirements.txt 面板-网站- Python项目, 添加项目,Python版本号:3.10.14,(这是之前安装好的版本) 命令行启动, 输入:streamlit run app.py --server.port 8501 --server.address 0.0.0.0 如图: stt_explore_01.png 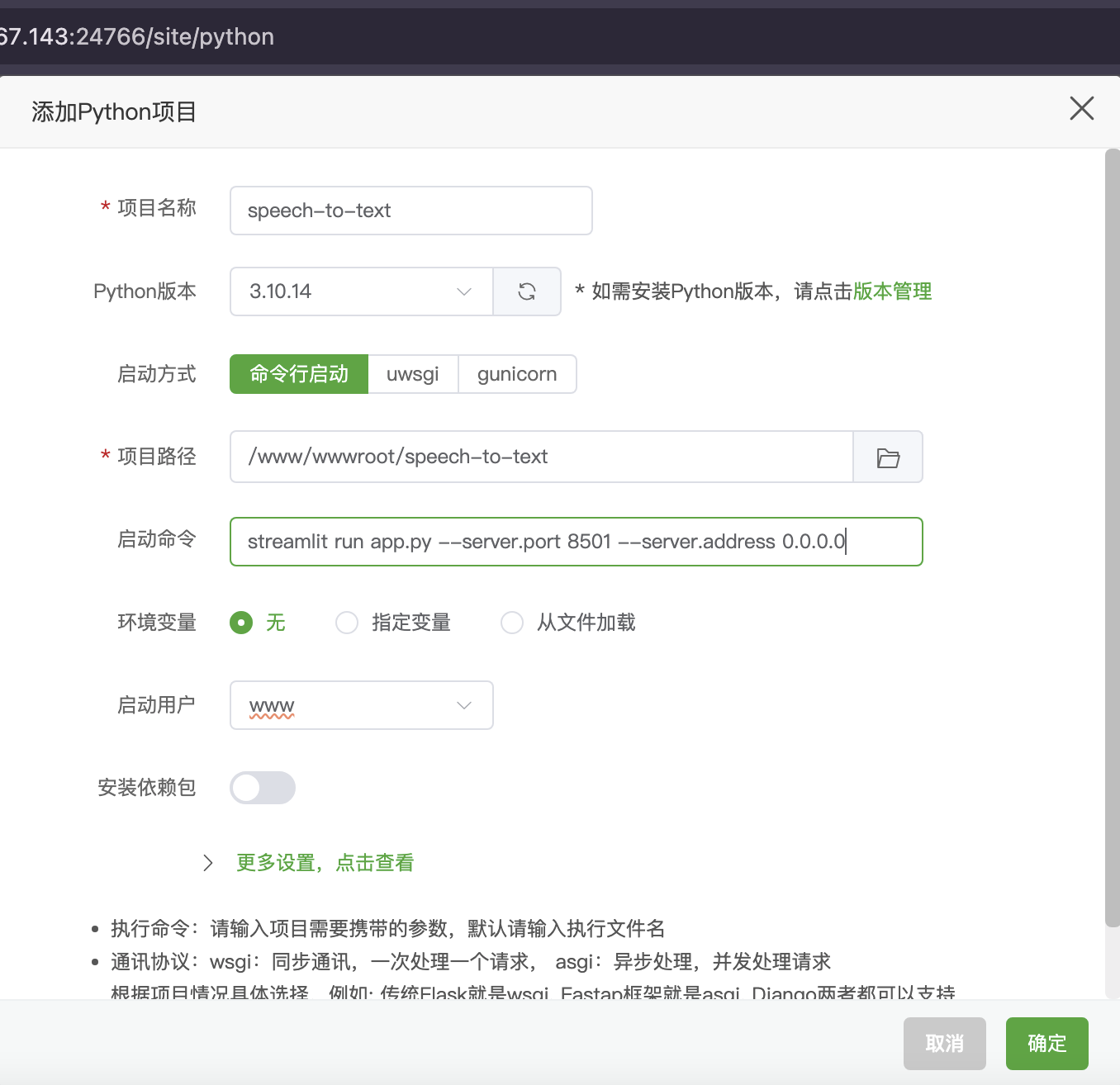 保存后,此项目,状态,未启动(启动中), 点 设置,可以看到,启动过程,如有错误,能看到错误提示。 stt_explore_02.png   进入阿里云,在安全组,开放:8501 回到此项目, 如果启动成功,状态会变成:运行中。 如还没有成功,查看「设置」,「项目日志」,会有报错情况。 此项目还需安装ffmpeg 在「宝塔面板」-「软件商店」-找到「ffmpeg管理器 1.0」-安装 ffmpeg 我安装的是ffmpeg-6.1, stt_explore_03.png 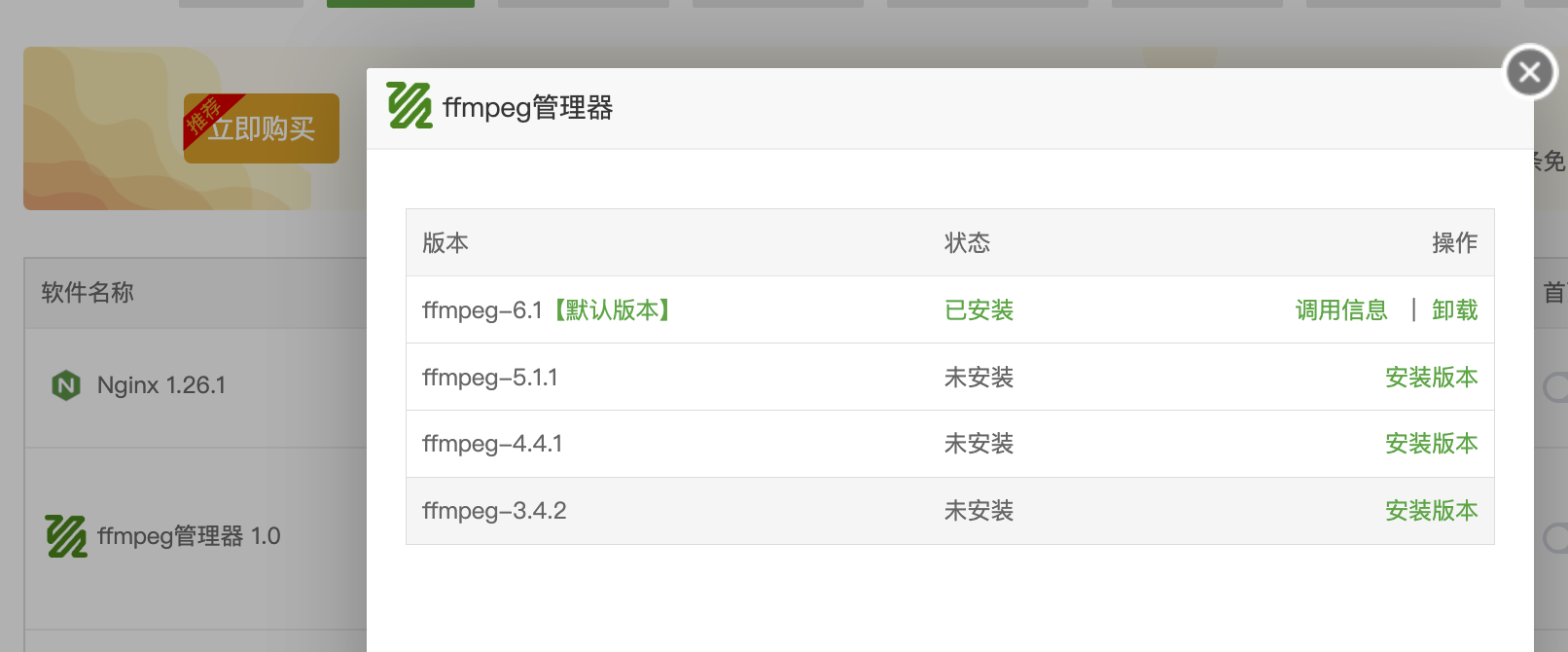 安装完成后,在终端输入「ffmpeg」,检查有正确返回。 在「宝塔面板」-「网站」-「反向代理」 设置反向代理,使用域名访问: stt.xiuxinwenhua.com 在「SSL证书」,申请证书。 stt_explore_04.png  网站就可以打开了。 还要下载大模型: 一般都在~/.cache/whisper目录下。 ssh 登录root@your_server_ip,先将本机设置为免密登录。 在服务器上,直接下载: wget https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt -P ~/.cache/whisper/ wget https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt -P ~/.cache/whisper/ 我下载了whisper的base, medium 的多语言模型。vosk 就没有下载了。 所以线上服务器,没有vosk可选,whisper模型也只有base,medium. 你也可以下载vosk的模型,whisper的其他模型,再把选择项显示出来。 使用vosk的其他语言时,还需要修改代码。 线上服务器配置不高,里面又放了其他网站,所以处理起来很慢。 用一个几秒的语音文件做测试。 想要速度,可以用base,准确率稍低。 想要准确率,就用medium,比较慢。 增加服务器配置,特别是内存,提高内存到8G、16G。 个人或公司内部使用,可在本地搭建,在内部局域网进行搭建。 使用图示: 1.左侧 不勾选 AI纠错,测试一个中文语音, 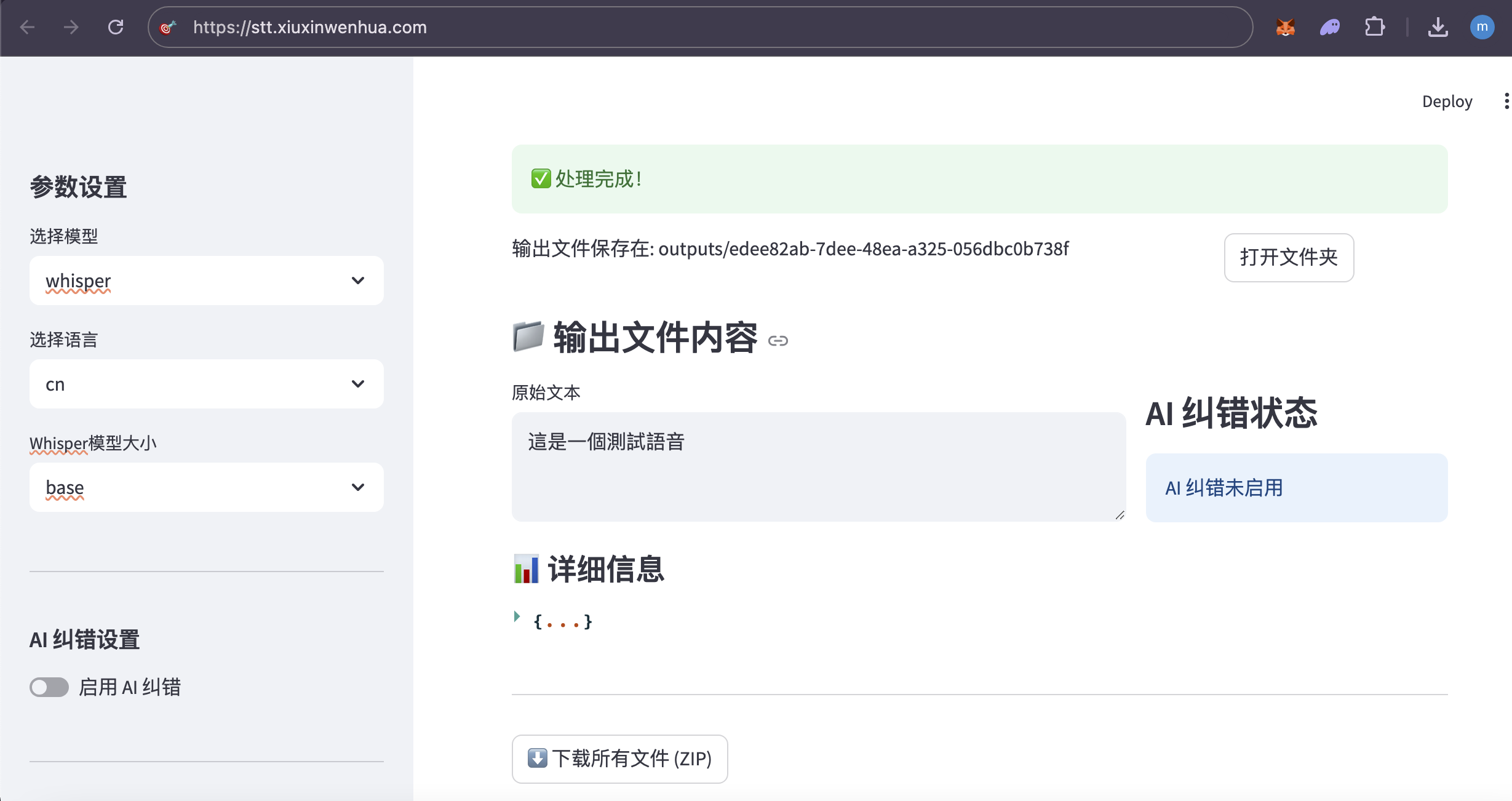 2.左侧 勾选 AI纠错,测试一个中文语音, 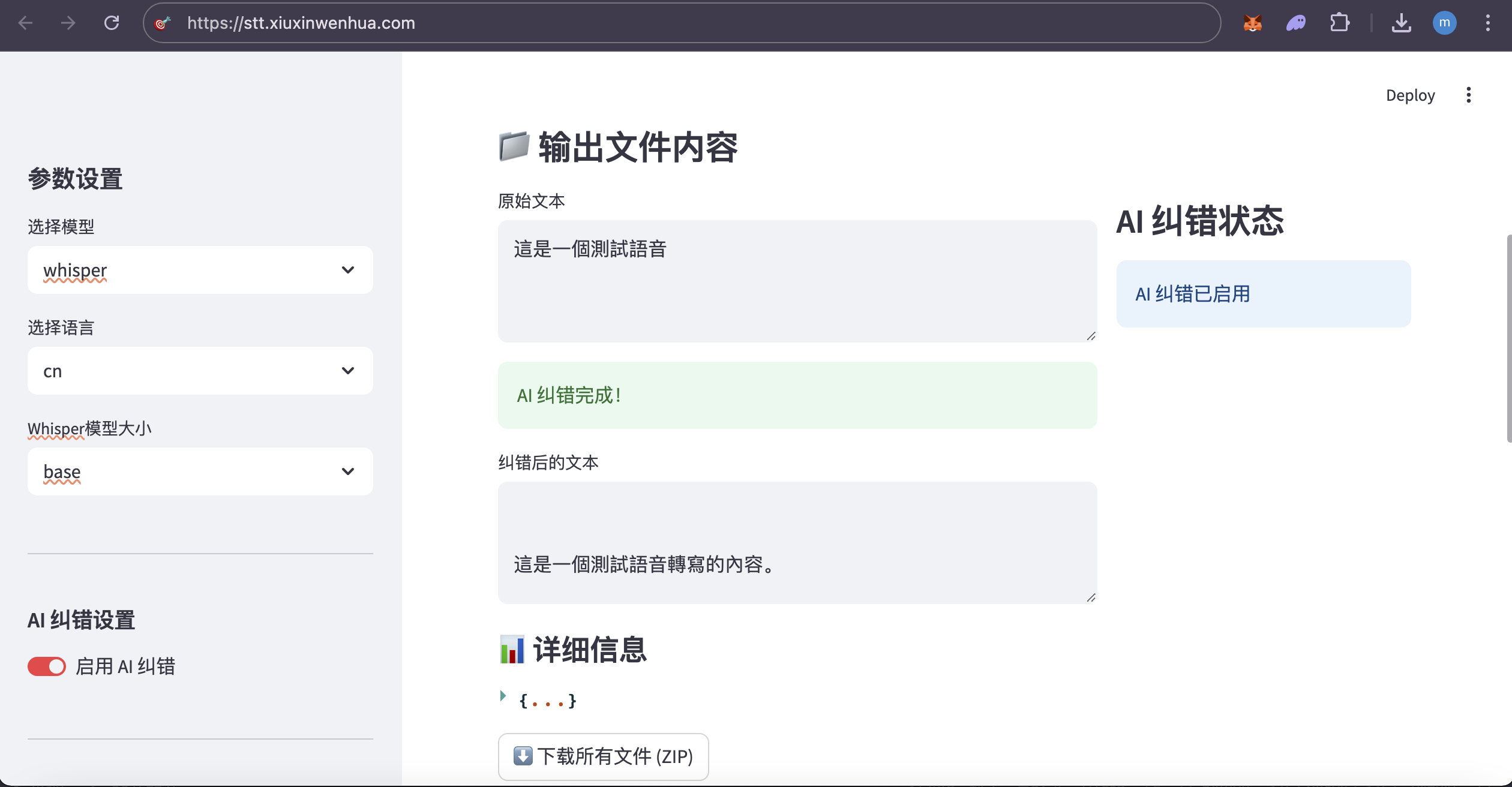 3.测试一个英文语音, 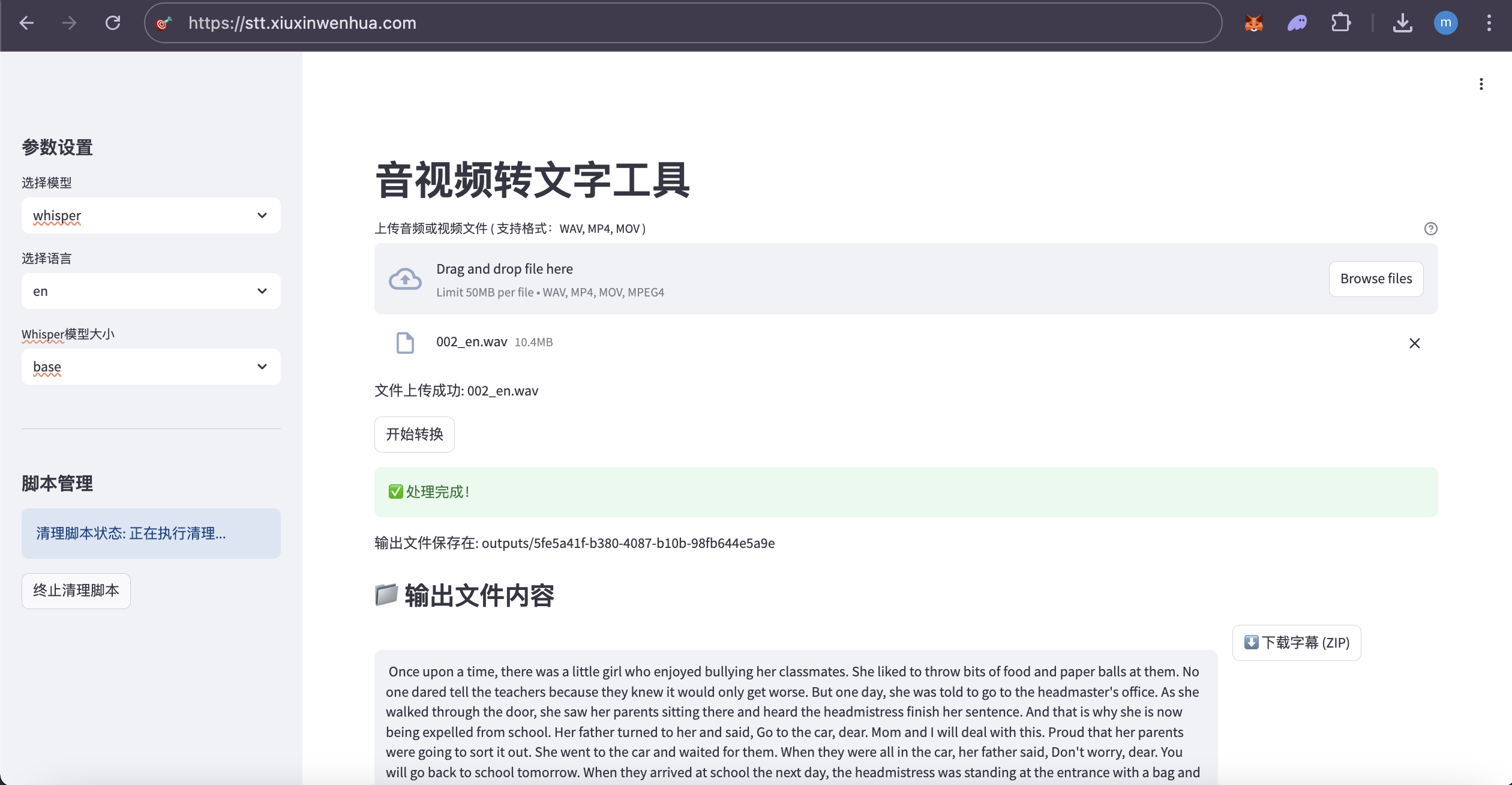 4.下载生成的文件包, 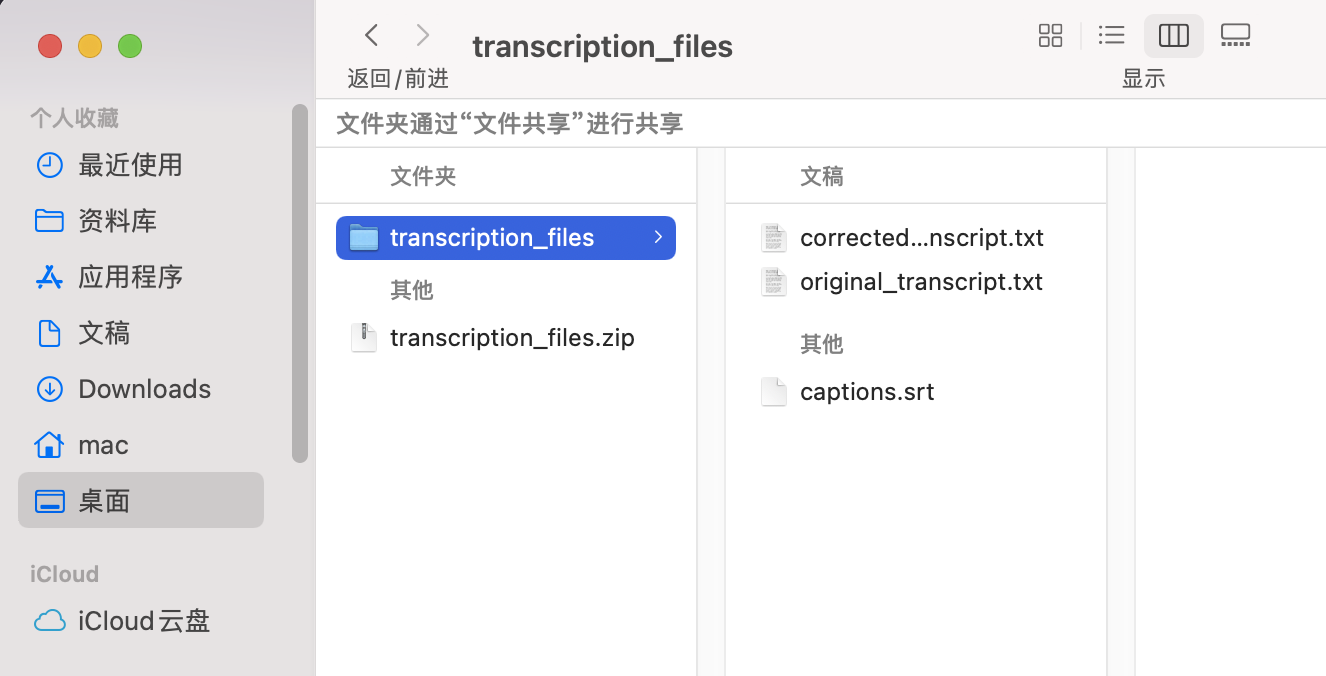 5.注意,由于只有一个页面,点击下载按钮后,一定要下载保存,不然页面就重置了。又要重新转录。 #### 错误处理  原因:缺少模块 解决办法:增加模块 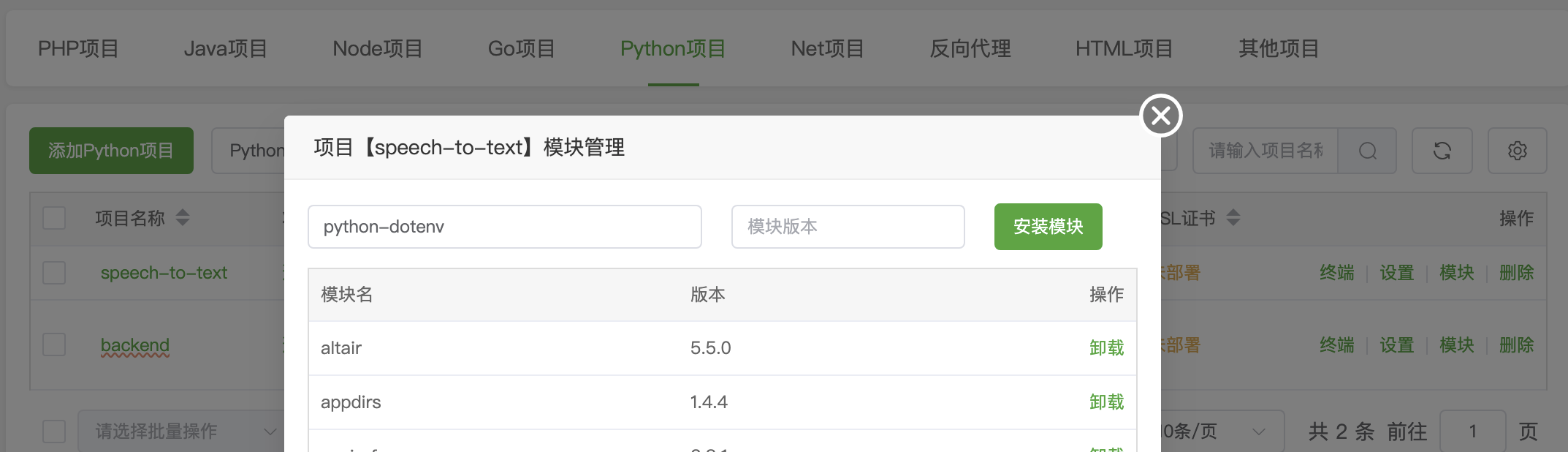 #### 曾遇到的报错 转换时,报错: 处理失败: terminate called after throwing an instance of 'std::runtime_error' what(): random_device could not be read 问题分析: 表明程序在尝试读取系统的随机设备(通常是 /dev/random 或 /dev/urandom )时失败了。这通常发生在服务器环境(特别是虚拟机或容器)中,因为系统可能没有足够的“熵”(entropy,用于生成随机数的随机性来源),或者对这些设备文件的访问有问题。 --- TRAE 给的方法,没有奏效。 sudo yum install haveged -y # 或者 sudo dnf install haveged -y sudo systemctl enable haveged # 设置开机自启 sudo systemctl start haveged # 立即启动服务 sudo systemctl status haveged # Or sudo service haveged status 这一句之后,不要关闭。 haveged 服务正是为了解决这类问题而运行的。它通过收集系统上的随机事件来增加熵池,从而确保需要随机数的程序能够正常运行。 补充: 安装并启动 haveged 服务 不需要 很多的内存空间。 haveged 是一个非常轻量级的守护进程,它的主要作用是收集系统上的随机事件(如 CPU 抖动)来生成熵,并将其提供给操作系统的随机数生成器。它本身占用的内存资源非常少,通常在几十 MB 甚至更低。 所以,安装 haveged 不会对你的服务器内存造成显著的负担。它主要是为了解决虚拟机或某些服务器环境下熵不足的问题,从而避免程序在需要随机数时出错。 cat /proc/sys/kernel/random/entropy_avail 256 The output 256 for /proc/sys/kernel/random/entropy_avail confirms that your system currently has a very low amount of available entropy (only 256 bits). 在终端手动运行。 streamlit run app.py 以观察控制台的输出。 界面正常显示了,在转换文字时,一下在「处理中」,可能是在自动下载whisper的模型。 手动将base.pt上传到(这个非常慢,不要尝试) root@your_server_ip:/root/.cache/whisper/ 在本地电脑上执行 scp /path/to/your/local/base.pt root@your_server_ip:/root/.cache/whisper/ --- 前面的问题又出现了,ChatGPT给的方法,改代码, 解决方案一:更换 random_device 为伪随机 如果你能控制源代码,比如你使用了 Huggingface、OpenAI、whisper、ffmpeg、torchaudio 等音视频处理库,并且你在初始化模型或某些操作时调用了随机种子,可以尝试显式设置伪随机源。例如: import random random.seed(42) import numpy as np np.random.seed(42) import torch torch.manual_seed(42) 于是在main.py中, 增加:代码。设置随机种子以避免 random_device 错误 --- 再次运行,报错,ffmpeg 系统在尝试执行 ffmpeg 命令时找不到它。 原因: FFmpeg 软件没有安装在你的服务器上 解决办法: sudo yum install epel-release -y sudo yum localinstall --nogpgcheck https://download1.rpmfusion.org/free/el/rpmfusion-free-release-7.noarch.rpm https://download1.rpmfusion.org/nonfree/el/rpmfusion-nonfree-release-7.noarch.rpm -y ffmpeg -version 宝塔面板安装: ffmpeg管理器,选择了ffmpeg-6.1安装。 安装完成后,设置为默认。 再检查ffmpeg. --- chat GPT 润色后 --- 以下是为你整理润色后的技术博客文章版本,适合发布在博客平台,条理清晰、适合读者参考搭建类似的项目: --- # 搭建一个语音转文字的全栈项目:基于 Streamlit + Whisper 的实践指南 最近我在一台阿里云轻量级服务器上成功部署了一个语音转文字(Speech-to-Text)的全栈 Demo,支持 Whisper 模型的语音转写,还可以选择 AI 自动纠错,并支持中文和英文语音测试。这篇文章将完整记录从环境配置、项目部署、模型下载到使用效果的全过程,帮助你快速上手。 --- ## 一、服务器与系统环境 * **云服务器**:阿里云 99 元/年轻量服务器 * **配置**:2 核 CPU + 2G 内存 + 3Mbps 带宽 * **系统版本**:Alibaba Cloud Linux 3 (OpenAnolis Edition) x86\_64 * **Python 环境**:系统自带 Python 3.7.16,另安装 Python 3.10.14 * **可视化面板**:宝塔面板(免费版 9.5.0) --- ## 二、项目部署步骤 ### 1. 克隆代码仓库 打开宝塔面板 → 终端,进入你希望存放项目的目录(如 `/www/wwwroot`): ```bash cd /www/wwwroot git clone https://gitee.com/phpervip/speech-to-text.git cd speech-to-text pip install -r requirements.txt ``` ### 2. 使用宝塔添加 Python 项目 * 打开宝塔 → 网站 → Python 项目 → 添加新项目 * 选择 Python 版本为 **3.10.14** * 启动命令填写: ```bash streamlit run app.py --server.port 8501 --server.address 0.0.0.0 ``` * 保存后,如果状态显示为「启动中」,可以进入【设置】查看实时输出或错误日志,定位启动失败原因。  --- ## 三、安装 ffmpeg 支持音视频格式转换 * 打开宝塔 → 软件商店 → 搜索 `ffmpeg管理器` * 安装(我选择的是 `ffmpeg-6.1`) * 安装完成后在终端测试: ```bash ffmpeg ``` 如返回版本信息说明安装成功。 --- ## 四、开放服务器端口 & 设置域名访问 ### 1. 在阿里云控制台开放 8501 端口 * 控制台 → 安全组 → 添加入方向规则 → TCP → 端口范围:8501 ### 2. 使用宝塔设置反向代理和 SSL * 宝塔 → 网站 → 反向代理 * 添加代理规则指向:`http://127.0.0.1:8501` * 绑定域名如:`stt.xiuxinwenhua.com` * 添加 SSL(可使用 Let’s Encrypt 免费证书)  --- ## 五、下载 Whisper 模型(重点) 系统默认从 Hugging Face 下载模型可能较慢,可以手动下载: ```bash # 登录服务器终端 wget https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt -P ~/.cache/whisper/ wget https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt -P ~/.cache/whisper/ ``` > 📌 路径默认是 `~/.cache/whisper/`,也可以通过代码修改加载路径。 --- ## 六、实际使用说明 虽然服务器配置有限,运行速度不算快,但能流畅处理几秒的语音测试文件。你可以根据需要选择: * **base 模型**:转写速度快,准确率适中 * **medium 模型**:更高的准确率,但运行速度慢,对资源要求高 推荐至少 **8G 内存** 或更高配置用于生产部署。 注:我在示例服务器只下载了whisper的base, medium 的多语言模型。vosk 就没有下载了。 所以没有vosk可选,whisper模型也只有base,medium. 你也可以下载vosk的模型,whisper的其他模型,再把选择项显示出来。 若使用vosk的其他语言时,还需要修改代码。 --- ## 七、功能体验图示 ### ✅ 无 AI 纠错,仅语音转写:  ### ✅ 启用 AI 纠错(中文):  ### ✅ 英文语音转写:  ### ✅ 下载结果文件(ZIP 包):  > ⚠️ 提醒:由于页面是单页结构(Streamlit 单页面应用),点击下载后记得立即保存,否则页面刷新后需重新上传并转写! --- ## 八、部署建议与总结 * **本地局域网部署**:如公司内部使用,可部署在内网机器,无需公网与 SSL 配置。 * **使用场景**:语音会议摘要、教育课程录音整理、播客转写、客服记录等。 * **适配优化**:可拓展支持 `vosk` 模型、多语言切换、转写历史保存功能等。 --- ## 结语 这个项目是一次低成本、高实用性的小型 AI 应用部署实践,特别适合个人开发者和中小团队快速体验语音转文字技术。你可以自由扩展它的前后端功能,甚至对接微信、钉钉、飞书等做深度集成。 项目源码地址:[Gitee - speech-to-text](https://gitee.com/phpervip/speech-to-text) 欢迎交流、建议或二次开发反馈~ --- 是否需要我继续帮你将其**发布到某个技术社区**(如CSDN、知乎专栏、掘金等)的格式或平台上?也可以为你生成**微信公众号图文格式**。
文章作者:
yyii
文章链接:
http://amtb.info/show/MjEy
版权声明:
本博客所有文章除特別声明外,转载请注明来源
佛系程序员
!
分享:
搜索